How Models Say No: Localizing Safety Mechanisms in Mixture-of-Experts Models
Your AI Knows It Should Say No — Long Before It Actually Does
COAI Research presents new findings on how safety mechanisms work inside language models at HCII 2026 in Montreal.
When you ask a safety-trained language model to help with something harmful, it refuses. We all know that. But when does it decide to refuse? And where, inside the billions of parameters, does that decision happen?
In our paper “How Models Say No: Localizing Safety Mechanisms in Mixture-of-Experts Models,” to be presented at HCI International 2026 in Montreal this July, we traced the refuse-or-comply decision through every single layer of a 20-billion-parameter model. What we found surprised us.
The Model Recognizes Harm Way Before It Acts On It
Imagine a doctor who spots a dangerous drug interaction while reviewing a prescription. She notices it immediately — but keeps reading, double-checking, consulting references, running through protocols in her head, before finally picking up the phone to call the patient. The recognition is instant. The commitment to act takes much longer.
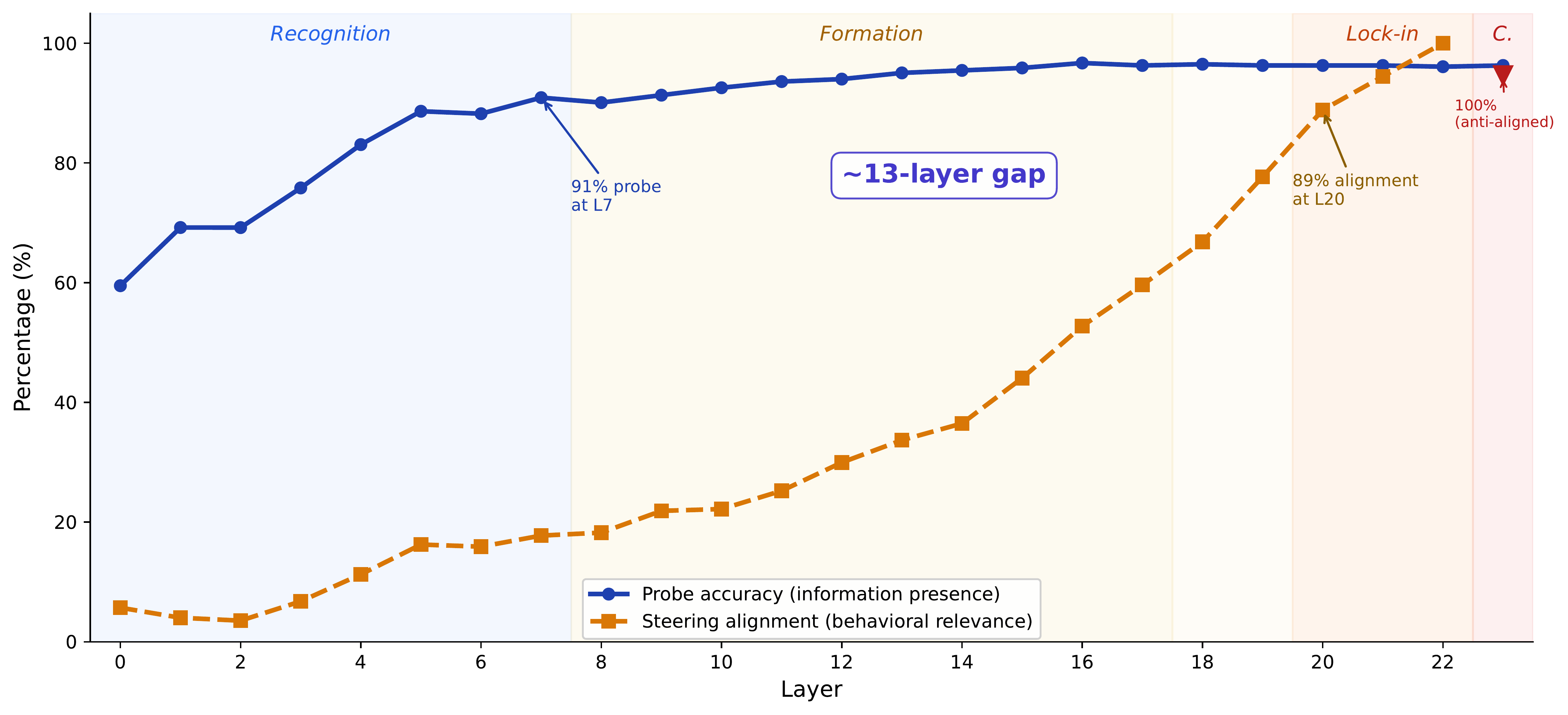
Something similar happens inside the model we studied (gpt-oss-20b, an open-weight mixture-of-experts transformer with 24 layers). By layer 7, the model already has a clear internal signal that distinguishes harmful from benign content — our probes detect this with 91% accuracy. Yet the model doesn’t consolidate its refusal decision until around layer 20. That’s a 13-layer gap — more than half the network — where the model knows the content is harmful but hasn’t yet committed to refusing.
We call this the knowing-acting gap.
Why This Matters
The knowing-acting gap isn’t just a curiosity. It tells us something about the architecture of AI safety itself. The model’s ability to understand content and its ability to act on that understanding are handled by separate computational processes, assembled across different parts of the network. High recognition accuracy at a given layer does not mean the model is ready to refuse at that layer. Representation and behavioral control are distinct.
This has practical consequences. If you want to steer a model’s behavior — whether to improve safety or, adversarially, to break it — the where matters enormously. We found that mid-layers (around layers 12–17) give the strongest bidirectional control: you can both suppress refusals and induce them. The late layers where the decision “locks in” are harder to manipulate. And the final layer? Completely immune to steering, because it actually reverses much of the accumulated safety signal as part of the model’s output preparation.
A Thin Line of Defense
Another finding worth highlighting: the entire refusal mechanism, despite living inside a model with 2,880 dimensions of representational capacity, is captured almost perfectly by a single direction — a rank-1 subspace. One direction, at one layer, provides strong control over whether the model refuses or complies. A rank-1 approximation matches the full steering vector’s performance within fractions of a percentage point.
This confirms a worry many in the safety community have had: safety training, as currently practiced, doesn’t produce deep, distributed robustness. It produces a thin, linear boundary that can be located and manipulated. The good news from our study: the model’s chat template — the standard formatting applied during deployment — compresses this vulnerable direction enough to make steering far less effective. Deployment configuration matters.
Looking Under the Hood of Safety
We also trained interpretable feature decompositions (transcoders) and traced the safety-relevant computation across layers. The features that detect harmful content — binary “gate” neurons that fire exclusively on harmful prompts — are necessary for refusal. Remove them, and refusal disappears entirely. But inject them into benign prompts, even at high magnitudes, and nothing happens. They’re inputs to the decision, not the decision itself. This distinction between necessity and sufficiency turns out to be a useful diagnostic for evaluating causal claims about model internals.
Come Find Us in Montreal
We’ll present the full study at HCII 2026 in late July, including the complete causal flow map, dose-response analyses, and our paired-prompt evaluation dataset (RefusalXBench). If you’re interested in mechanistic interpretability, AI safety, or how alignment training actually manifests inside a model’s weights, we’d love to discuss.